

Postup Googlu při překladu
Překlad například z angličtiny do češtiny řídí dva tzv. modely. Překladový model pro
anglická slova vybírá možné české protějšky a jazykový model z těchto
kandidátů vybere toho, který do vznikající české věty nejlépe zapadne. Tyto
dva modely překlad vytvářejí současně a svůj výběr nezakládají jen na tom slově,
které se právě překládá, ale i na předchozích čtyřech. Kupříkladu mějme k přeložení
větu, kde jsme se v překladu dostali do této situace:
Originál: „…others also accused of plotting…” Překlad: „…další také obviněn z ???”
Máme už kus českého překladu a teď hledáme překlad slova „plotting”. Překladový model
nabízí několik alternativ seřazených podle četnosti výskytu, například: 1) mapování
2) parcelace 3) vynášení 4) spiknutí a mnoho dalších. Jazykový model pak vyhodnotí „obviněn
z mapování”, „obviněn z parcelace”, atd. jako málo pravděpodobné a protlačí
na první místo „spiknutí”. Kromě tohoto hlavního postupu je ještě proces překladu
oživen a vylepšen tím, že program si nepamatuje jen toho jednoho výherce (zde „spiknutí”),
ale první čtyři, takže u dalšího slova si může své rozhodnutí ještě rozmyslet. To se stalo
i v našem příkladě, kde původně vyhrálo „z” jako pravděpodobnější než „ze”, ale výběr „spiknutí”
toto původní rozhodnutí zvrátil. Přitom to není tak, že Google by „věděl” něco o pravidlech,
kdy se v češtině používá „z” a kdy „ze”, pro něj jsou to dvě nesouvisející česká slova,
přičemž na českém internetu se „z spiknutí” prakticky nevyskytuje,
zatímco „ze spiknutí” ano. Google se dokonce ani nesnaží identifikovat slovní druhy,
rody, pády, čísla, ani nalézt ve větách přísudek a další větné členy.
Chyby
Z tohoto postupu pak vyplývají i typy chyb, kterých se překlad dopouští. Na dvou náhodně vybraných
textech jsem překlad vyzkoušel a některé symptomatické chyby vybral:
- Magie s negací:
- „but was unable” je přeloženo jako „ale byl schopen” místo „ale nebyl schopen”,
protože „was” má silnou tendenci překládat se jako „byl”. Celkově lze říct, že rozdíly v používání
negace nejsou v tomto přístupu nijak řešeny a spoléhá se tu pouze na statistiku. Tato chyba však
není považována za závažnou: narozdíl od běžného člověka, který větu se zcela obráceným smyslem považuje
za velmi nepovedený překlad, z pohledu Googlu je chybně jen jedno slovo, což je skvělý úspěch. - Věty nevěty:
- „The US authorities say they have…” je přeloženo jako „Orgány USA, že se…” Při
jiném způsobu překladu zohledňujícím strukturu věty by se celkem jednoduchá věta s přísudkem „say”
nemohla přeložit na českou větu, ve které se žádný přísudek nevyskytuje. - Gramatická neshoda:
- „…it is thought the chancellor may now feel…” je přeloženo jako
„…to je mysleli, že kancléřka může nyní cítí…”, což porušuje základní pravidla o časování
českých sloves.
Další chyby jsou takové, že by proti nim nepomohl ani překlad s využitím větné struktury:
- Cizí jména:
- „Walled bin Attach, a Yemeni national who, according to the Pentagon, has admitted…” je
přeloženo jako „Zděný bin Připojit se jemenská národní kteří, podle Pentagonu, přiznal…” Zajímavé tu je,
že „bin”, ačkoliv také běžné anglické slovo, přeloženo není, je tedy považováno za součást jména. Místo toho,
aby se systém buď rozhodl pro jméno, nebo se to celé rozhodl přeložit,
zvolil střední cestu, která je jistě špatně, ale při vyhodnocování překladu
podle počtu správných slov má takto největší naději na slušné skóre. Stejnou chybou trpí
i jiné překladové systémy. Můj oblíbený příklad je „Gumák jako voják”,
který se ale za poslední roky viditelně zlepšil a už ani v přehledu vyznamenání nemá
„rytíř záchoda”. - Příliš důkladný překlad:
- Symbol £ je do češtiny převeden jako €,
což čtenář překladu jen těžko odhalí jako chybu. Stejně tak „English” může
být přeloženo jako „česky”, což je někdy správně, ale někdy taky ne. - Přeskakování rodů:
- V průběhu jednoho textu je „chancellor”
překládáno občas jako „kancléř”, jindy jako „kancléřka”. Projevuje se
tak skutečnost, že to, co se při překladu rozhodlo před více než čtyřmi
slovy, nemá žádný vliv na současné rozhodnutí. Funguje to přibližně tak,
že pokud je v blízkosti slova „chancellor” vlastní jméno, bývá rod ve shodě s rodem
křestního jména, jinak vítězí „kancléřka”, protože se na českém internetu
vyskytuje častěji než „kancléř”.
Kde můžeme čekat zlepšení
Překlad Googlu je zatím nejlepší díky obrovskému množství dat, které dokáže pro tvorbu modelů využít,
a díky schopnosti zpracovat tato data efektivním způsobem. Tam, kde ostatní používají trojice slov,
Google využívá pětice (tedy při rozhodování o pátém slově do statistiky zahrnuje předchozí čtveřici).
Stejných pět slov za sebou se ale nevyskytuje příliš často. Pokud vybereme anglické
texty o velikosti 13 milionů slov a zapamatujeme si z nich všechny vyskytující se pětice slov, zjistíme,
že při čtení nového textu uvidíme 94% pětic slov poprvé a jen zbylých 6% už budeme znát z oněch předchozích
13 milionů slov. Tak moc jsou lidé při psaní originální! Proto také překladové systémy pětice nepoužívají,
protože zabírají spoustu místa v paměti a v 94% případů jsou na nic. S tím se ale Google nespokojil a
zkusil přidat dat víc. Výsledek je vidět na následujícím obrázku: při zvětšování dat se situace zlepšuje, na obrázku
je vidět, že zdvojnásobení velikosti dat přidává k původním 6% další dvě až tři procenta. Googlu se podařilo
počet dat zvýšit na dvojnásobek osmnáctkrát za sebou, až do celkové velikosti dat 2·10¹² slov, při které už
je u nového textu 56% pětic slov už známých. K tomu je ovšem třeba pamatovat si 300 miliard různých pětic,
které se v těch 2·10¹² slov vyskytovaly. Dámy a pánové, nechci se vás dotknout, ale komu z vás se tohle vejde
do paměti počítače?
Google se rozhodně snažil, aby pamětí zbytečně neplýtval, a přesto k uložení pětic a rychlému přístupu
k nim potřeboval 1800GB rozdělených mezi 1500 počítačů.
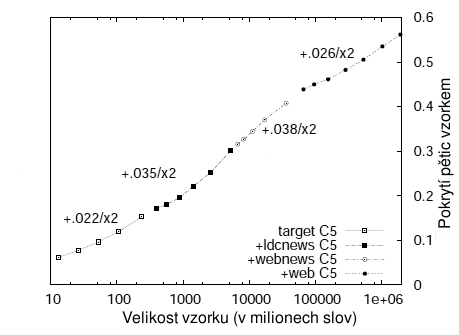
Tento výsledek je povzbudivý, protože ukazuje, že má smysl snažit se
zdvojnásobit velikost sbíraného textu a zajistit si tak o 3% lepší pokrytí
výsledného modelu, který bude rozhodovat o tom, jestli nová pětice má smysl
větší, nebo menší. Před publikací tohoto výsledku se vědělo, že od určité
velikosti textu se pokrytí už dále začne zvyšovat jen zanedbatelně a zdálo se,
že tato hraniční velikost textu je přibližně někde v řádu milionů slov. Tento
článek na pražské konferenci ale ukázal, že tato „hranice zbytečnosti
zvětšování dat” je vzdálenější, než bychom hádali. Otázkou ale je, kolikrát se
ještě může podařit zdvojnásobit velikost nasbíraného textu, než narazíme na to,
že víc toho lidé prostě zatím anglicky nenapsali. Úskalím je i skutečnost, že
ne každý jazyk má tolik psaných kulturních památek (čti webových stránek), aby
bylo možné k němu vyrobit takto použitelný model založený na pěticích slov.
Zatím tedy Googlu k udržení náskoku stačí sbírat víc a víc textu ve všech
perspektivních jazycích. Až je víceméně nasbírá, jeho překladový systém
bude přesto stále dělat chyby, které jsou při této metodě nevyhnutelné. Tyto
chyby může v budoucnu odstranit jen systém, který bude více dbát na smysl a
koherenci výstupního textu. Jsem upřímně zvědav, zda se v tomto směru
někomu podaří Google předběhnout a zda poskytnutí tohoto systému k použití
zdarma učiní konec automatickým překladům, jako je tento.
Námět k článku: Franz.
Odkazy
- Demonstrace překladu: http://translate.google.com/translate_t?sl=en&tl=cs
- Celý článek vědců z Google Research: http://acl.ldc.upenn.edu/D/D07/D07-1090.pdf